Aggregate-Transform-Persist+Publish (ATP) Architecture for Webhook Integration
TLDR; Extract-Transform-Load (ETL) for Events
Introduction
Integrating with third-party SaaS webhooks (for example, TicketSpice ticketing events or Viator booking notifications) poses significant architectural challenges. Each provider delivers event data in different formats and expects our system to handle these HTTP callbacks reliably and securely. A generic Aggregate-Transform-Persist+Publish (ATP) architecture addresses these challenges by providing a reusable pipeline for ingesting webhooks, transforming them into a common format, and persisting and distributing the events internally. The ATP pattern is motivated by the need for a robust, scalable approach to webhook consumption – one that decouples external providers from internal systems, handles the asynchronous nature of webhooks, and accelerates onboarding of new integration partners.
In webhook-based integrations, external systems send events asynchronously and often expect a quick acknowledgment without waiting for full processing. (For instance, TicketSpice explicitly notes that “Webhooks are not delivered in real-time and should not be relied on for real-time or synchronous workflows.”.) This means our system must process webhooks asynchronously and reliably, buffering and handling failures gracefully. Moreover, without a unifying architecture, integrating each new provider can lead to ad-hoc code, duplicated efforts, and brittle coupling between systems. The ATP architecture solves these problems by aggregating events from multiple sources into one pipeline, transforming each event into a canonical internal schema, and persisting events for durability and downstream consumption. In the following sections, we’ll explore the motivation for this pattern, walk through the high-level design (with ASCII diagrams), delve into each component, and discuss implementation strategies. We’ll also consider extensibility for new providers, key trade-offs in the design, and the strategic business benefits of adopting an ATP webhook integration architecture.
Motivation and Context for the ATP Pattern
Webhook integrations are fundamentally event-driven: third-party SaaS applications emit events (e.g. “new ticket sold” or “booking confirmed”) to notify your system. Without a unified approach, a company might implement each webhook consumer separately – parsing provider-specific payloads and directly invoking internal logic. This ad-hoc approach quickly becomes problematic as the number of integrations grows. Different webhooks have inconsistent schemas, authentication methods, and delivery guarantees, making it hard to ensure reliability and maintainability across the board.
The Aggregate-Transform-Persist+Publish pattern is motivated by several needs:
- Decoupling and Resilience: We want to decouple external providers from internal services. In a naive integration, if an internal service is slow or down, the webhook might timeout or be lost. By inserting an aggregation and queueing layer, we buffer incoming events and respond immediately to the provider, protecting against downstream slowness. This prevents external SLA mismatches from breaking our system. In industry best practice, introducing a message queue or bus to decouple event producers and consumers is crucial for reliability. It allows the producer (the SaaS webhook) to send events at any speed while our system processes them at its own pace, ensuring one slow consumer doesn’t back up the others. As one integration expert notes, “All cloud providers have an events bus... utilize them to handle dispatching and routing of messages.” This decoupling via an event bus is a core feature of the ATP architecture.
- Schema Variations and Transform (Anti-Corruption Layer): Each third-party webhook has its own JSON (or XML) schema. Without a canonical model, every internal consumer would need to handle each provider’s format. The ATP pattern introduces a transformation layer that acts as an anti-corruption boundary between external and internal representations. It translates each provider’s payload into a canonical event schema that our internal systems understand. This shields our core business logic from external schema changes and quirks. For example, System 2 might implement an “anti-corruption layer” to translate System 1’s webhook payload into System 2’s internal model – in our case, the transform step performs this translation universally for all providers. The result is a stable, versioned internal event format that downstream systems can code against, rather than chasing each provider’s evolving API.
- Reliable Delivery and Idempotence: Webhook senders typically deliver events with at-least-once guarantees – meaning duplicates are possible if acknowledgments fail or network issues occur. As Hookdeck’s guide notes, “Most webhook providers operate on an ‘at least once’ delivery guarantee… you will eventually get the same webhook multiple times.” Our architecture needs to gracefully handle retries and duplicate events without causing duplicate processing in our system. The ATP design addresses this by tracking event IDs and ensuring idempotent processing (discussed later in Idempotency strategies). Combined with persistence, this means even if the same event arrives twice or processing needs a retry, the outcome remains correct and side-effect free.
- Persistence and Audit: By persisting both raw and transformed events, we gain an audit log and the ability to replay or debug events. Raw event storage means if something goes wrong – say a new field from Viator wasn’t handled correctly – we still have the original payload and can reprocess it after fixing the code. It also provides traceability: we can always inspect what data was received from the provider (which aids troubleshooting and compliance). Persistence of canonical events provides a durable event log that can feed analytics or be queried for insights over time, independent of the real-time bus. This level of durability and traceability is a key motivation for the “Persist” aspect of ATP.
- Scalability and Partner Onboarding Speed: A generic ATP service becomes a webhook hub for the organization. Once in place, adding a new provider (say, integrating Eventbrite or another SaaS) is much faster – you primarily configure a new endpoint and mapping, leveraging the same proven pipeline. This plug-and-play extensibility means faster partner onboarding (which in business terms means faster time-to-value for new integrations). Rather than reinventing the wheel for each partner, the organization invests once in the ATP infrastructure and reuses it, increasing ROI with each added integration.
In summary, the ATP architecture is needed to solve reliability, scalability, and maintainability issues inherent in webhook integrations. It turns the problem of many disparate, vendor-specific webhooks into a streamlined event processing pipeline. The next sections present the architecture’s design and internals in detail.
High-Level System Design
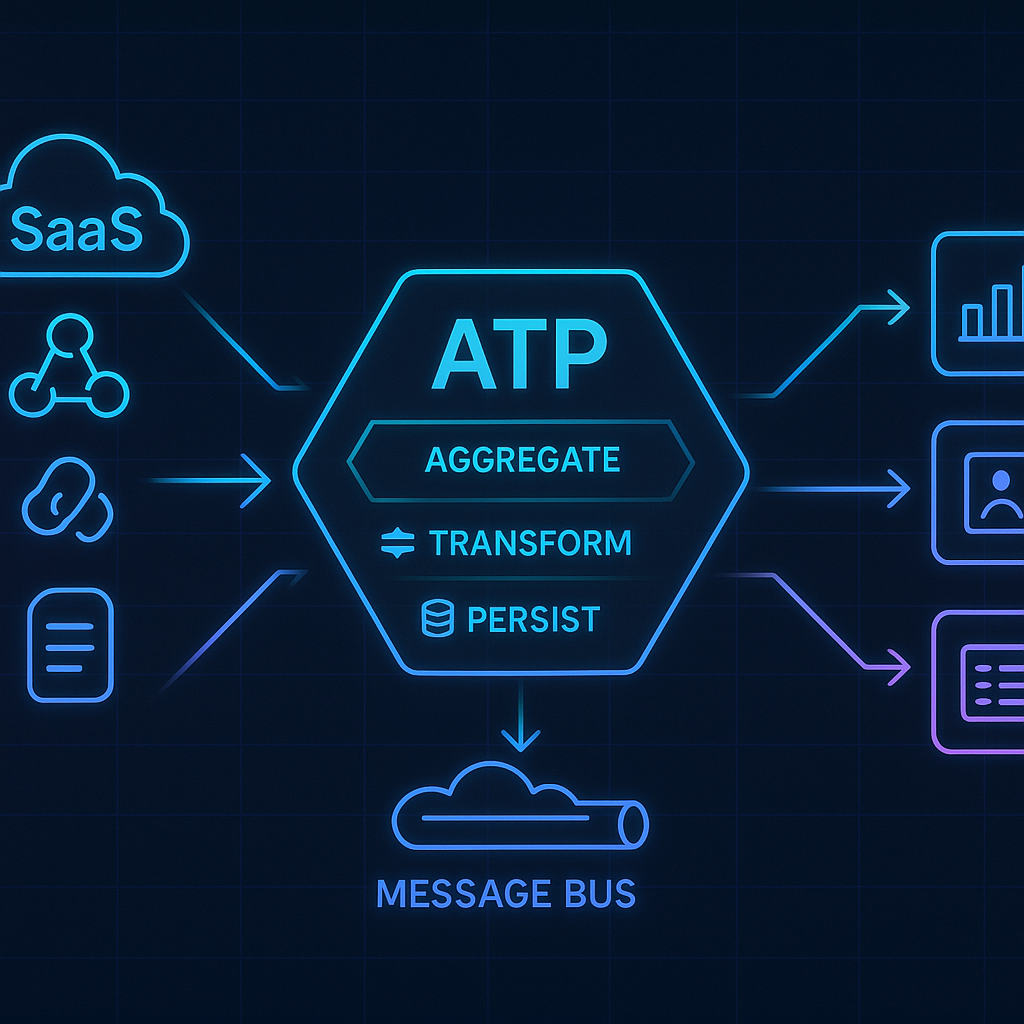
At a high level, the Aggregate-Transform-Persist+Publish architecture introduces a pipeline that every incoming webhook follows. The system can be visualized as three logical stages: ingestion, processing, and distribution. Multiple third-party sources feed into a centralized webhook hub (the ATP core), which in turn publishes unified events to an internal bus that fan-outs to subscribers. The ASCII diagram below illustrates the main components and data flow:
+------------------------+ +---------------------------+ +----------------------+
| Third-Party Providers | ----> | ATP Core Service | ----> | Internal Event Bus |
| (TicketSpice, Viator, | HTTP | (Aggregate, Transform, | Pub | (Pub/Sub or Message |
| etc. via webhooks) | | Persist pipeline) | | Broker topics) |
+------------------------+ +---------------------------+ +----------------------+
/ | \
(Multiple internal systems subscribe to events)
High-level ATP architecture: external SaaS webhook producers send HTTP requests into our ATP core, which aggregates and processes events, then pushes standardized events to an internal message bus. Downstream services (consumers) subscribe to the bus to receive the events relevant to them. This design cleanly separates concerns: external-facing webhook endpoints are handled in the ATP core, and internal consumers simply listen on the bus for canonical events, without needing direct knowledge of external providers.
A typical flow is as follows: TicketSpice or Viator (or any new provider we integrate later) will be configured to send webhooks to our system’s designated URL. The ingestion layer of the ATP core receives those HTTP calls. Instead of processing them synchronously (which could timeout or slow down the provider), the ATP core quickly acknowledges receipt and offloads the work to an internal queue. The processing layer then picks up the queued event, performs transformations (mapping the data to our canonical schema, aggregating any extra info if needed), and persists the results. Finally, the processed event is published onto the message bus (e.g. an enterprise Service Bus topic, an AWS SNS/EventBridge topic, or Google Pub/Sub), where any number of internal services can consume it asynchronously. Each stage can scale independently – e.g. multiple ingestion endpoints, multiple processing workers, etc. – making the system elastically scalable and robust against spikes or slow components.
Internal Processing Flow: From Webhook Ingress to Bus Egress
To understand the internals more concretely, let’s walk through the lifecycle of a webhook event as it travels through the ATP pipeline. The diagram below outlines each step from the moment a webhook arrives to the point it is delivered to internal consumers:
Third-Party Webhook (HTTP POST from provider)
|
v
[ Ingestion Endpoint (per provider) ]
|--- Verify signature (security check)
|--- Respond 200 OK immediately to sender
|--- Persist raw event (for backup/audit)
`--- Enqueue event for async processing
v
[ Aggregator/Transformer Service ]
|--- Deduplicate (idempotency check)
|--- Transform payload to canonical schema
|--- Persist canonical event (event store)
`--- Publish event to internal bus
v
[ Internal Event Bus (Pub/Sub) ]
|
`--- Fan-out delivery to multiple consumers (subscribers)
Let’s map this flow to a concrete example. Suppose a TicketSpice webhook is sent when a new ticket is sold. In Step 1, the HTTP request hits our Webhook Ingestion Endpoint for TicketSpice. The endpoint immediately validates the request’s authenticity (Step 2 – e.g., checking the HMAC signature using TicketSpice’s secret) and sends back a 200 OK response to acknowledge receipt. This quick ack is critical because most webhook producers operate in a fire-and-forget style – they won’t wait long for processing. In fact, many providers enforce a strict timeout on responses, so our endpoint does the minimum required work and returns a success promptly.
Before returning, the ingestion logic persists the raw event payload (Step 3) and enqueues a message (Step 4) for further processing. The raw event (often JSON) might be stored in a blob storage or database as-is, tagged with an ID and timestamp. Enqueuing can be done via a message broker or queue (for example, an Azure Service Bus queue, AWS SQS, Google Pub/Sub topic, etc.) that decouples the incoming HTTP thread from downstream processing. At this point, the external provider’s responsibility is done – they got a 200 response – and our system takes over asynchronously.
In Step 5, a dedicated Aggregator/Transformer service (the core of our processing layer) pulls the event from the queue. This component is designed to handle events from any provider in a unified way. It first performs an idempotency check (Step 6) to see if this exact event has already been processed. For example, if Viator retried a webhook and sent it twice, the transformer would detect a duplicate (using a unique event ID or hash) and skip or short-circuit processing the second time. (We’ll discuss idempotency strategies in detail later – e.g., using a database of processed IDs with a unique constraint to avoid double-processing.)
If the event is new, the service then transforms the raw payload into our canonical schema (Step 7). This involves mapping provider-specific fields to our standard fields. For instance, TicketSpice might send {"fn":"John","ln":"Doe"} for a name, whereas our canonical format expects {"customer":{"firstName":"John","lastName":"Doe"}} – the transform layer handles such mappings. This step serves as an anti-corruption layer isolating external data models from internal logic. The transformation may also enrich the event: e.g., adding a source identifier (“source: TicketSpice”), timestamp normalization, or even calling out to the provider’s API for additional info (if the webhook only gave an ID, for example).
After conversion, the system persists the canonical event (Step 8) in a datastore. This could be a relational or NoSQL database table that stores all canonical events (perhaps indexed by event type and date) for auditing and querying. We now have two records of the event: one in raw form and one in standardized form – providing full traceability.
Finally, in Step 9, the transformed event is published to the internal message bus. In a cloud environment, this might be publishing a message to a topic (e.g., an AWS SNS topic, an Azure Service Bus Topic or Event Grid, or GCP Pub/Sub topic). The message contains the canonical event data and metadata (like type, source, ID, etc.). The message bus then distributes the event to all subscribed internal systems (Step 10). For example, you might have a “Sales Analytics” service subscribed to all “ticket.sold” events, and a “CRM Sync” service also listening for the same events – they will both independently receive the event from the bus. This fan-out via pub/sub means multiple downstream processes can react to the event in parallel, without the upstream having to call each one directly.
Critically, the bus decouples the timing and load of event consumption. If one consumer (say, a legacy system) is slow, the message bus will buffer events for it without slowing down other consumers. Our transform service doesn’t need to know or coordinate between consumers; it simply hands off the event to the bus. Using an event bus is a cloud-recommended approach to handle routing and throttling of events in such integration scenarios.
To summarize, the internal flow ensures that from the moment a webhook is received, it is validated, recorded, transformed, and delivered reliably to where it needs to go – all in an asynchronous, fault-tolerant manner. Next, we’ll dive deeper into each component of this architecture and discuss how to implement them.
Webhook Ingestion Endpoints
Webhook ingestion endpoints are the entry point of the ATP pipeline – they are HTTP endpoints that third-party providers call to deliver webhook events. In this architecture, you will typically set up separate endpoints for each provider (or each context) to simplify processing and security. For example, you might have routes like /webhooks/ticketspice and /webhooks/viator (each configured in TicketSpice or Viator’s settings respectively). These endpoints can be implemented as lightweight HTTP handlers, cloud functions, or API Gateway routes that forward to a Lambda/function, etc., depending on your infrastructure. The key is that each endpoint knows how to authenticate and accept requests from its designated provider.
Important responsibilities of the ingestion endpoint include:
- Authenticity Validation: Verify that the request truly came from the provider and not a malicious actor. Usually, this means checking a signature or secret. Most SaaS webhook providers supply a signing secret and include an HMAC signature in each request header. The endpoint must compute the HMAC of the request payload (often using SHA-256 with the shared secret) and compare it to the signature header. Only if they match do we consider the webhook valid. This prevents unauthorized or tampered calls from entering our system. (In addition, one can employ IP allowlisting or token checks if the provider supports it, but cryptographic signatures are the strongest guarantee.)
- Quick Acknowledgment: As noted, webhook senders typically expect a fast response. Many will retry or mark the delivery as failed if they don’t receive a 2XX response within a few seconds. Our endpoint handler should therefore avoid doing heavy processing inline. Instead, it should quickly log the receipt, perform the cheap verification steps (authenticating the signature, perhaps some basic schema validation), and then enqueue the event for downstream processing. After enqueueing (or handing off to a background task), it immediately returns an HTTP 200 OK. This design acknowledges the event before doing the slow work, aligning with the “fire-and-forget” model of webhooks (producers send and don’t wait for full processing). By doing so, we minimize the chance of timeouts and duplicate retries from the provider.
- Minimal Transformation or Logic: The ingestion endpoint should remain as simple as possible – essentially just a pass-through to the pipeline. It might do very light normalization (e.g., parse JSON into a structured object) or attach metadata (like tagging the event with the source = “TicketSpice”), but it should not contain business logic or complex transformations. That is delegated to the aggregator/transform stage. Keeping endpoints simple has two benefits: (1) it reduces the chance of errors or slowness at the ingress point, and (2) it makes adding new endpoints for new providers straightforward (each new endpoint is just a thin wrapper that feeds the common pipeline).
- Enqueueing or Triggering Async Processing: In many implementations, the endpoint will place the raw event onto a message queue or stream. For example, the handler might publish a message to an AWS SQS queue or an Azure Service Bus queue/topic that serves as the intake buffer. In serverless architectures, another pattern is to have the API Gateway or function directly invoke the next step (e.g., an EventBridge or a background function) without an explicit queue – but conceptually it’s the same: the goal is to hand off the event to an asynchronous processing channel. This decoupling ensures the rest of the processing can happen reliably even if it takes time, and the provider has been released from the HTTP call quickly.
- Raw Data Persistence: Optionally, the ingestion component can persist the raw webhook data immediately upon receipt (before enqueueing). This could be writing the JSON payload to a storage bucket or database as is. Doing so at the ingestion stage guarantees that even if subsequent processing fails or the system crashes, the original webhook payload is not lost – we have it stored for later inspection or reprocessing. In some designs, this raw persistence is done in the transform stage instead (after pulling from the queue), but doing it right at ingress can be simpler: we record exactly what we received at the earliest point. The raw event store acts as a “black box recorder” for all incoming webhooks.
To implement the ingestion endpoints in a reusable way, consider using an Infrastructure-as-Code (IaC) approach to define them. For instance, you might use Terraform or CloudFormation scripts to create an API Gateway and a set of Lambda functions (one per provider) or a containerized microservice that routes to different handler functions. This ensures that your dev, staging, and prod environments have the same endpoint configurations. It also makes it easy to spin up new endpoints for additional providers by cloning or templating the IaC definitions (more on IaC in Implementation Strategies). Each endpoint will have its own security configuration – e.g., store each provider’s webhook secret in a secure store (AWS Secrets Manager, Azure Key Vault, etc.), which the function uses to verify signatures.
In summary, the ingestion layer is your front door for webhooks. It should be secure, fast, and dumb (do very little). By performing only the necessary gatekeeping (auth and enqueue), it sets the stage for the heavier lifting to be done in a controlled, async environment deeper in the pipeline.
Aggregation and Canonical Transformation Logic
Once an event has been handed off by the ingestion layer, it enters the aggregation and transformation stage – the core of the ATP pipeline. This component (often implemented as a service or set of workers) is responsible for pulling in events from all sources, homogenizing them, and preparing them for distribution. It’s called an “aggregator” because it handles events from multiple webhook providers, funneling them through one unified process. Let’s break down its responsibilities:
- Consuming from the Queue: The aggregator service reads incoming events from the queue or stream where the ingestion endpoints placed them. This could be a continuous process (e.g., a long-running worker, or serverless function triggered by queue messages, or a Kubernetes deployment of consumers). The system may have multiple instances for throughput, but conceptually they do the same work: take an event off the queue and begin processing it. At this point, the event is typically still in the provider’s raw format (perhaps wrapped in a minimal envelope with metadata like source).
- Idempotency and Deduplication: Before doing any heavy work, the service should check if this event has already been processed. As mentioned, webhook providers might retry deliveries, resulting in duplicate messages in our queue. The aggregator implements idempotent processing – ensuring a given event (identified by a unique ID or combination of properties) only has an effect once. A common strategy is to maintain a “processed events” store (for example, a simple SQL table or a Redis set) of event IDs that have been seen. When a new event comes in, the service checks the ID against this store. If it’s present, the event is a duplicate and can be skipped (or handled in a special way, such as just confirming it). If it’s not present, the service adds the ID to the store and proceeds. Many providers include a unique event ID in the payload or headers (e.g., Shopify sends an
X-Shopify-Webhook-Idheader); if not, the service might construct a hash of the payload as a surrogate ID. By enforcing uniqueness (often via a database unique constraint or key), we automatically handle the “at least once” delivery nature of webhooks – the same event won’t be processed twice. This step is crucial for preventing downstream side effects from duplicating (imagine two identical “order paid” events causing double fulfillment – idempotency guards against that). - Aggregation (if needed): In some scenarios, “aggregation” might involve combining data from multiple events or sources. In the simplest interpretation, our aggregator is just collecting events from all providers into one pipeline. But you might have cases where related events need to be merged or ordered. For example, if a provider splits a large payload into two webhook calls, you might want to aggregate them before producing a canonical event. This can introduce complexity (requiring correlation IDs and state), and many systems avoid it by designing webhooks to be self-contained. However, our architecture keeps the door open for such logic if necessary. Generally, aggregation here means multi-source handling – the service can handle TicketSpice, Viator, and any new provider’s events through configuration or plugins. Each new source doesn’t need a brand new service; the aggregator is built to load the mapping rules or module for that source and process accordingly.
- Transformation to Canonical Schema: This is the heart of the logic. For each incoming event, the service invokes the appropriate transformation routine to convert it from the provider’s format to the canonical event format used internally. We design a canonical schema that covers the needs of all our event types across providers. This schema could be a custom JSON structure or something standard like a CloudEvents JSON envelope. The canonical event typically includes meta-fields like
eventType(e.g., "Ticket.OrderCreated"),source(e.g., "TicketSpice"),timestamp,id(a unique ID, possibly the provider’s ID or a generated UUID), and adataobject containing the event details in a normalized structure. We also include any relevant context that all events should carry (trace IDs, user IDs, etc.). By standardizing on a canonical event envelope, we make it far easier for internal systems to consume events, since they have a consistent structure and metadata. As a best practice, this canonical schema should be versioned – include a version number or schema version – so that it can evolve over time without breaking consumers (more on versioning below).Each provider will have a mapping logic: e.g., for TicketSpice’s “New Registration” webhook, map its fields to aRegistrationCreatedcanonical event; for Viator’s “Booking Confirmed”, map to, say, aBookingConfirmedcanonical event. This mapping can be coded (e.g., with if/else or strategy classes for each provider+event type) or configured via metadata (e.g., a JSON mapping file or a JOLT template) depending on complexity. The transformation stage may also perform data enrichment – for example, adding a lookup of a customer name from an ID, if our internal event needs that and the webhook only had an ID. However, be cautious with enrichment that requires outbound calls (to a database or back to the provider’s API) as it can slow down processing; use caching or design events to carry what’s needed whenever possible. - Persistence of Processed (Canonical) Events: After transforming the event, the service persists the canonical event to the event store. This is a database or storage where we keep all events in their unified form. The persistence serves multiple purposes: it provides an audit log of all processed events (which internal team can query), and it acts as a backup for replays. If later a downstream system needs to reprocess events (say, it was down and missed some, or a new service wants to load historical events), they can be retrieved from this store. The canonical store might be as simple as an append-only log table with columns for event ID, type, timestamp, source, and a JSON blob of the data. Because this data is in canonical format, it’s easier for analysts or developers to use directly than raw provider data. Storing canonical events is somewhat optional (since the events are also on the bus), but it greatly aids debugging and future-proofing. It’s analogous to a data lake of events that the company can use for analytics or reprocessing without needing to touch the raw data unless absolutely necessary.
- Publishing to the Message Bus: Finally, the aggregator/transformation service emits the canonical event into the internal message bus (also considered the persist step in the sense of persisting to the event streaming system). This involves creating a message with the standardized event and sending it to the appropriate topic or exchange. In a simple design, there could be one topic for all events (consumers filter by eventType or source). In a more advanced design, you might have multiple topics or channels partitioned by domain or event type (for example, an "orders" topic for all order-related events across systems, a "payments" topic for payment events, etc.). Partitioning can help with scaling and organizing subscribers. Either way, the transform service doesn’t need to know who the subscribers are; it only needs to know which bus/topic to publish to. Once published, the event is in the hands of the message bus for delivery.
One of the key design goals of the aggregator/transform logic is to make it extensible. We want to be able to integrate a new webhook source with minimal changes: ideally by just adding a new mapping function or config for that provider, and maybe a new endpoint feeding into the same queue. The core pipeline (queue, processing engine, bus) remains unchanged. To achieve this, you can structure the code using a strategy pattern or plugin architecture: define an interface like WebhookTransformer with a method transform(rawEvent) -> canonicalEvent. Provide implementations for each provider’s event types. The aggregator service can then look at the source field (e.g., “Viator”) and eventType (e.g., “BookingCreated”) on the raw event metadata to dispatch to the correct transformer. This way, adding a new provider means writing a new transformer class (or even just adding mapping rules to a config file) but no change to the overall service orchestrating the process.
Another aspect to consider is error handling in transformation. If the transform logic encounters an unexpected format (say a field is missing or the payload doesn’t match the expected schema), it should handle it gracefully: log the error, and possibly push the event to a dead-letter queue (DLQ) for manual review. It’s better not to drop events silently. By capturing failures in a DLQ, operators can later examine those events, fix the code or mapping, and replay them. Indeed, a robust webhook system will use DLQs to collect failed messages for retry. We’ll discuss observability and error handling more in a later section, but in the transform stage one should consider how to bubble up errors without crashing the whole service (e.g., catch exceptions per message so one bad event doesn’t stop the processing of others, and route the bad event to an error queue/store).
In summary, the aggregation/transform component is the workhorse of the ATP architecture. It generalizes the processing of any webhook into a consistent sequence: deduplicate -> translate -> save -> publish. By centralizing this logic, we ensure all providers benefit from the same reliability features (idempotency, logging, etc.) and produce the same quality of output (canonical events) for our internal ecosystem. It reduces the integration of a new webhook to a mapping exercise, rather than building a brand new pipeline each time.
Persistence Layer for Raw and Canonical Events
The persistence layer in the ATP architecture refers to storing events durably at two stages: (1) storing the raw webhook events as received, and (2) storing the canonical events after transformation. This layer underpins the reliability, replayability, and auditability of the system.
Raw Event Storage: As discussed, raw events can be persisted at the ingestion stage (or just after pulling from the queue in the transform stage). The goal is to capture the exact payload and metadata that the third-party provider sent. This is typically stored in a write-once log – for example:
- An Object Storage approach: Save each raw event as a file (e.g., JSON file) in a storage service like AWS S3, Azure Blob Storage, or Google Cloud Storage. You might use a naming convention like
/{provider}/{eventType}/{year}/{month}/{day}/{eventId}.jsonor a GUID for the filename. Object storage is cheap and virtually unlimited, making it good for archiving large numbers of events. Access can be slower for ad-hoc queries, but we usually won’t query raw events frequently – they are mainly for backups and occasional debugging. - A Database Table approach: Insert raw events into a database (SQL or NoSQL). For instance, a table
raw_webhook_eventswith columns:id(event ID),provider,event_type,received_attimestamp, andpayload(JSON or text). This makes it easier to query recent events or filter by provider/type in case of debugging (“show me all TicketSpice Registration events from yesterday”). However, a high volume of webhooks could make this table grow very large, so careful indexing and partitioning (or retention policies) are needed. A NoSQL document store (like MongoDB or DynamoDB) could also serve, keyed by event ID.
The raw store ensures data integrity – if something goes wrong downstream, we haven’t lost information. It’s analogous to keeping raw logs. For example, if a consumer says they missed an event or something looked off, we can retrieve the raw JSON that was sent and verify. It also allows reprocessing: if we ever need to regenerate canonical events (due to a code bug fix or a new derived field we want to populate), we can take raw events from the archive and run them through the transform logic again.
One thing to manage is retention – raw events may not need to be kept forever. Depending on business needs, you might keep, say, 30 days or 1 year of raw events easily accessible, and then archive older ones or delete them if not needed (especially if they contain sensitive data, you might not want to hoard indefinitely). Alternatively, if compliance requires, you may keep them but secure and segregate access.
Canonical Event Storage: After transformation, we store the event in its canonical form as well. This might seem redundant given we also publish to the bus, but it serves distinct purposes:
- It provides a single source of truth internally for all events in a normalized form. If someone in the company asks “how many bookings were confirmed last week?” or “show me the details of ticket order #12345 from TicketSpice,” you could answer that by querying the canonical events store, without needing to aggregate disparate systems or parse raw data.
- If new internal services come online, they might want to replay historical events. Having canonical events stored means you can backfill or replay to them easily (since the events are already in the format the new service expects). This is hugely valuable for onboarding new consumers or recovering from extended outages. For example, if a new analytics service is deployed, you could dump last year’s canonical events from the DB and publish them to the bus to train the new service’s cache or state.
- The canonical store can feed batch processing or analytics pipelines (like loading into a data warehouse). Because the data is uniform, you can run meaningful analysis on it (e.g., all events have a
sourcefield so you can break down events per source, etc.).
Implementation of the canonical store often uses a database. A SQL database might hold a table events with columns like event_id, event_type, source, timestamp, payload (JSON), and possibly a processed_at timestamp. An index on event_type or source could allow selective queries. If volume is extremely high (millions of events per day), a scalable solution like a big data store (e.g., Hadoop/Spark or BigQuery, depending on context) might be considered, but typically a moderate relational DB or a time-series DB can handle a considerable stream if sized properly.
One must also plan how to uniquely identify events across raw and canonical storage. Ideally, each event gets a stable ID (perhaps the provider’s event ID if provided, or else a generated UUID we attach at ingestion). We can use that to cross-reference raw and canonical records (e.g., store the same id in both places). This also helps with idempotency: the ID is what we check for duplicates and also the primary key in stores to ensure no duplicates.
Ensuring Consistency: It’s worth noting the order of operations in the pipeline regarding persistence. A possible approach is: ingest -> put on queue -> (transform) -> store canonical -> publish to bus. If storing canonical succeeds but publishing fails (e.g., bus is temporarily down), we should have a mechanism to retry publishing (perhaps via the same or separate queue) so that eventually the event gets out. Similarly, if publishing succeeded but storing canonical failed (maybe DB issue), we still delivered the event but lost our canonical log. In practice, one might invert those steps: publish to bus first, then attempt to store canonical. If storing fails, at least consumers got the event (and we could later reconstruct missing canonical entry from raw store if needed). Designing for these failure modes can be complex – using transactions or outbox patterns can help, but typically, the likelihood of such partial failures is low with proper cloud services (and if it happens, a DLQ captures it for manual reconciliation).
Finally, Dead Letter Queues (DLQs) and retry logs are also part of persistence from a error-handling perspective. If an event consistently fails processing (say our transform code throws an exception even after retries), that event might be moved to a dead-letter queue. The DLQ is a form of persistence for failed events. Operators can inspect the DLQ messages (which contain the raw event and error info) to debug the issue. Once fixed, those events can be replayed from the DLQ or from the raw store. In either case, the system should not just drop an unprocessable event; persisting it in a DLQ ensures no data is lost, even if it couldn’t be handled immediately.
In summary, the persistence layer of ATP gives the architecture memory. It remembers what happened (raw and canonical forms), providing durability beyond the transient life of a message in a queue. This supports reliability (crash recovery, no lost events), debuggability (audit trail), and flexibility (replays, new consumers, analytics). While it introduces storage overhead, the strategic value of data retention in integrations is high – you gain insights and confidence that nothing silently disappeared.
Integration with the Message Bus
The message bus (or event bus) is the distribution backbone of the ATP architecture. After events are aggregated and transformed, the bus is responsible for delivering them to any internal systems that care about those events. This final stage makes our architecture event-driven and loosely coupled. Let’s discuss how the ATP core integrates with the message bus and why this is so powerful.
Role of the Message Bus: The message bus decouples producers (our ATP pipeline, in this context) from consumers (various internal services). Instead of the transform service calling specific APIs or functions in each consuming system, it simply publishes a message to a central event stream. The bus then fans out that message to all subscribers. Subscribers independently handle the events at their own pace. This architecture yields multiple benefits:
- Multiple Consumers, Zero Coupling: Many internal systems can consume the same event without the producer needing to know about them or send multiple requests. For example, a
TicketSoldevent might be used by a finance system (to update revenue), an email system (to send a confirmation), and an analytics system (to record metrics). With a bus, the ATP core just emits oneTicketSoldevent, and all three systems receive it. If later a fourth system wants it, we just add a subscription; no change needed to the producer. This publish-subscribe model is excellent for scalability in organization structure as well – teams can build new consumers for events without interfering with the team that owns the integration core. - Asynchronous and Buffered Delivery: Message buses typically provide some buffering and retry capabilities. If a consumer is temporarily offline or slow, the bus can hold messages for it (depending on the technology, e.g., an AWS SNS with SQS subscriptions, or Kafka retains messages until read). This means one slow consumer doesn’t block the pipeline or other consumers. Our transform service can publish and move on, without waiting on any consumer. In essence, the bus acts as an event distribution buffer, smoothing out differences in processing speed and availability. Alex Dorand highlighted that by using an event bus, “System 1 can pass events at any speed… Messages then get streamed to an event bus [which] filters the events based on the target and delivers [them].” In our scenario, “System 1” is the ATP core and downstream systems are like System 3 or 4 in that example – the bus ensures we handle different SLAs gracefully.
- Filtering and Routing: Modern event buses (like Azure Event Grid, AWS EventBridge, Google Eventarc/PubSub) often have built-in filtering and routing rules. This means subscribers can choose to receive only certain events based on content. For instance, a service could subscribe to only “Viator” events, or only “OrderCreated” events, etc., using metadata filters, rather than receiving everything. The bus can do this filtering efficiently. In practice, one might have separate topics for broad categories (to avoid too much noise), but filtering adds flexibility. For example, Azure Service Bus topics support subscribers with SQL-based filter rules on message properties, and AWS EventBridge lets you specify event patterns to match on fields. This capability makes the architecture flexible: you can publish all canonical events, and each consumer will only get what it’s interested in, either by subscribing to the relevant topic or by applying a filter.
- Reliability and Ordering: Enterprise message buses usually guarantee at-least-once delivery to subscribers and often preserve ordering per topic or per key. If event ordering matters (say events related to the same ticket should be processed in order), the bus can often accommodate that by use of message grouping or partitioning keys. For example, Kafka and AWS Kinesis allow partitioning by a key (like ticket ID) to ensure order per key. Azure Service Bus has the concept of session IDs to group messages. In our design, if ordering is important for certain event streams, we can design the publishing to include an appropriate key. If not, events can be consumed in the order they were published (which, for independent events, is usually fine). The point is, the bus gives us knobs to handle such requirements that a naive point-to-point integration would struggle with.
- Technology Choices: The question references Service Bus, SNS, Pub/Sub – indeed there are many options:
- Cloud-native services: AWS EventBridge or SNS+SQS, Azure Service Bus or Event Grid, Google Pub/Sub, etc. These are managed services that provide topic semantics.
- Open source / self-hosted: Apache Kafka (very common for high-throughput event streaming), RabbitMQ (if more small-scale or on-prem needs), or even Redis streams. The choice depends on throughput, ordering, and fan-out requirements. For example, Kafka provides high throughput and persistent log of events (so consumers can join later and replay from history within retention), whereas SNS+SQS provides a simpler fan-out with persistent queues per consumer but no long-term retention by default.
- The ATP architecture is agnostic to which bus you use, as long as it supports pub-sub delivery. However, cloud providers’ native buses integrate nicely with other services and IaC, so often it’s wise to use them. As Alex Dorand noted, “All cloud providers have an events bus… it is best to utilize them to handle dispatching and routing of messages.”.
- Security on the Bus: Since the message bus is a central conduit of internal data (which could include sensitive information from webhooks), it’s important to secure it. Typically, this means access control such that only authorized services can publish or subscribe to certain topics. For example, your ATP core service should be the only thing allowed to publish to the “webhooks events” topic, and perhaps only specific consumer services are allowed read access. Cloud buses often have built-in Role-Based Access Control (RBAC) or use IAM roles/policies (e.g., AWS IAM policies on EventBridge or SNS, Azure RBAC on Service Bus). We configure these so that one team’s service can’t accidentally (or maliciously) consume events it shouldn’t, and no external entity can access the bus at all. All communication with the bus should be internal and ideally encrypted in transit (most managed buses enforce TLS). In summary, principle of least privilege is applied: each component gets just the rights it needs on the bus.
Integrating the ATP core with the bus is usually straightforward: use the bus SDK or API in the transform service to publish messages. For instance, using AWS SDK to publish an SNS message, or Azure SDK to send to a Service Bus topic. This call would happen after successful transformation. One consideration is error handling: if the bus publish fails (e.g., network glitch or service outage), the transform service should retry a few times or send the event to a retry queue. These failures are rare in managed cloud environments, but the code should account for it. Often, a simple retry loop with exponential backoff solves transient issues. If it ultimately fails, that event could land in a DLQ or flagged for manual intervention.
On the consumer side (though that’s beyond the scope of our integration pipeline per se), each internal service will have its own subscription or queue. They will handle events asynchronously as well. The advantage for consumers is they don’t have to implement webhook-specific logic; they receive clean canonical events which are easier to work with. Also, if a consumer needs to be taken down for maintenance, it can catch up later from its queue without the events being lost – the bus decoupling ensures resilience across system boundaries.
In summary, the message bus turns our architecture from a point-to-point integration into a fully event-driven system. It brings extensibility (multiple consumers, easy to add new ones), resilience (buffering, retries, decoupling), and flexibility (filtering, scaling). The ATP core effectively acts as a producer on the bus, and the rest of the enterprise can act on the events as needed. This not only solves the immediate integration use case (getting data from SaaS into our systems), but also lays the groundwork for broader event-driven workflows (other systems could also publish to the bus, and so on, building an ecosystem of events).
Having covered the primary components of the ATP architecture – ingestion endpoints, transform logic, persistence, and the message bus – we’ll now explore some important implementation strategies and best practices that cut across these components to ensure the system is robust, maintainable, and secure.
Implementation Strategies and Best Practices
Designing the architecture is one part of the story; implementing it in a consistent, repeatable way is equally important. In this section, we discuss key strategies and practices for building and operating the ATP webhook integration system. These include leveraging Infrastructure-as-Code for deployment, defining canonical schemas and managing their evolution, ensuring idempotency and deduplication, handling event reprocessing, setting up observability, and enforcing security at various levels. Together, these practices ensure that the ATP pipeline is not only well-architected but also cleanly implemented and manageable in the long run.
Infrastructure-as-Code (IaC) and Service-as-Code
To achieve a deployable and consistent architecture, it’s highly recommended to manage the entire ATP system using Infrastructure-as-Code (and the related concept of Service-as-Code). IaC means that all cloud resources and infrastructure components (API endpoints, queues, databases, message bus topics, etc.) are defined in code and can be deployed in an automated way. For example, you might use Terraform, AWS CloudFormation, Azure Bicep/ARM templates, or Google Cloud Deployment Manager to script the setup of your webhook endpoints, security groups, queues, functions, and so on. Service-as-Code extends this idea to the configuration of the services themselves – meaning you treat the configuration and deployment scripts of your microservices as code in your repository (sometimes this just falls under the DevOps practice of having everything version-controlled).
Using IaC yields several benefits:
- Consistency Across Environments: You can replicate the whole pipeline in development, staging, and production with minimal differences. This allows testing the full integration flow in lower environments with test webhooks. It also prevents the “it works in prod but not in stage” issues due to manually configured differences – everything is from the same templates.
- Repeatability and Speed: Onboarding a new provider might involve deploying a new endpoint or a new function. With IaC, that’s as simple as adding the new endpoint definition and re-applying the configuration. There’s no manual clicking in consoles, which speeds up the process and reduces human error. For instance, adding a TicketSpice endpoint might be a few lines of code specifying an API Gateway route and lambda, which can be deployed in minutes through CI/CD.
- Versioning and History: All changes to the infrastructure go through code reviews and are versioned in your VCS (Version Control System). If a change causes problems, you can roll back to a previous version of the infrastructure definition. This is crucial for a critical integration service – you want to be able to track changes to topics, queues, etc., over time.
- Service Catalog and Reuse: With Service-as-Code, you might create templates or modules that can be reused. For example, a Terraform module for “webhook_endpoint” could encapsulate creating an API Gateway route, linking it to a Lambda, setting up the IAM role with least privilege for that lambda (to put to queue, etc.), and setting environment variables (like the provider’s secret). Then for each new provider, you just instantiate this module with different parameters. This encourages a standardized setup for all providers.
A concrete example: You decide to deploy on AWS. You use AWS SAM or AWS CDK (which are IaC frameworks) to define an API Gateway with routes for /webhooks/{provider} that trigger a Lambda function. The Lambda code is the same for all (it routes based on provider parameter), or you deploy separate Lambdas per provider – either way defined in code. You also define an SQS queue, an SNS topic (as the bus), a DynamoDB table for idempotency keys, etc. You wire them (Lambda sends to SQS, another Lambda consumes SQS, publishes to SNS, etc.) all in the IaC template. This whole infrastructure can then be spun up in a test account with one command. Microsoft’s Azure or Google Cloud similarly could be defined via Terraform or ARM templates; and if using Kubernetes, you’d define deployments and services in YAML. No matter the stack, the principle is the same: “document” the system in executable code rather than relying on manual setup or tribal knowledge.
This approach also ties into CI/CD (Continuous Integration/Continuous Deployment): when you update your code or config, your pipeline can run tests and then apply the IaC changes to update the environment. For instance, if you add support for a new event type in the canonical schema (like a new field), you might also add a new column in a database – the IaC template would handle that migration or addition.
In addition, a LinkedIn engineering article pointed out that having a secure cloud landing zone includes automated infrastructure as code so that components like the event bus and logging are consistently configured for security and ops from the start. This is a good reminder that IaC isn’t just about convenience – it’s also about baking in best practices (security groups, network settings, monitoring) into your definitions so every environment meets your organization’s standards.
In summary, treat the ATP architecture as a product of code. The servers, queues, and pipelines are not hand-crafted snowflakes; they are defined and managed through code. This gives you the foundation for a reliable and easily extensible integration platform.
Canonical Schema Definition and Versioning
One of the most critical pieces of your design is the canonical event schema – the format that all webhook events are transformed into. Defining this schema clearly and managing its evolution over time is essential for a stable integration architecture.
Defining the Schema: Start by analyzing the event types from the providers you have (TicketSpice, Viator, etc.) and identify the common concepts. Typically, you might end up with a set of canonical event types that correspond to business events (e.g., OrderCreated, OrderCancelled, PaymentProcessed, TicketCheckedIn, etc. depending on domain). For each event type, design a JSON (or XML or Avro or Proto, but JSON is common for flexibility) structure that contains the fields needed by consumers. Include standard metadata for all events:
- A
typeoreventTypefield, e.g."Ticket.OrderCreated"or some namespaced string. - A
sourcefield, e.g."TicketSpice"or"Viator", to know where it came from. - A
timestamp(and possiblysourceTimestampif the time the provider recorded the event is useful). - An
id– a unique identifier for the event in our system (could incorporate source and their ID). - Possibly a
correlationIdor trace ID if events can be correlated (e.g., an OrderCreated and subsequent OrderCancelled could share an orderId). - The
dataobject: the payload with fields relevant to the event. Here, use consistent naming and structure. For example, if both TicketSpice and Viator have a concept of a customer name and email in their webhooks, in canonical form you might have"customer": { "name": "John Doe", "email": "john@example.com" }no matter the source. If some provider lacks a field that others have, you might leave it null or provide a default. Conversely, if one provider has extra info that others don’t, you have to decide if it fits into the canonical model (maybe as an optional field) or if it’s dropped/not represented. The goal is not to lose important information, but also not to make the canonical schema a lowest-common-denominator that’s too sparse. It’s a balancing act – often you include superset of fields, marking some as optional for sources that don’t have them.
A good practice is to base your schema on an industry standard if one exists. The CloudEvents specification is one such standard: it defines a common structure for events (with fields like type, source, id, time, etc. and an extension mechanism for custom data). Using CloudEvents JSON format could be beneficial because it’s language-agnostic and has broad support. Whether or not you explicitly use CloudEvents, the concept of an event envelope with metadata plus payload is wise.
Schema Definition Format: You should formalize the schema, e.g. with a JSON Schema document or OpenAPI-like specification for the events. This allows validating transformed events against the schema – a sanity check that your transform logic is outputting correctly. It also allows you to generate documentation for internal consumers (so they know what fields to expect) and even code (using tools to generate data classes from schemas, if using strongly typed languages). In complex organizations, maintaining a central “events catalog” is helpful.
Versioning Strategy: No matter how well you design the schema initially, requirements will change. You might need to add new fields, deprecate some, or handle changes in providers’ data. It’s important to have a versioning strategy to avoid breaking consumers:
- Backward-compatible changes (additive changes) can often be done without bumping a major version. For example, adding a new optional field is usually fine – old consumers ignoring it and new consumers can use it. However, you should communicate such changes to consumers (maybe via release notes of the integration platform).
- Breaking changes (like removing or renaming a field, or changing semantic meaning) should ideally be avoided. If absolutely needed, consider introducing a new event type or a new version identifier. For instance, you could introduce
OrderCreated.v2as a new type, or include aschemaVersion: 2field in events. The publisher (ATP core) could then publish both versions for a transition period, or consumers can switch to listening for the new type when ready. - In some systems, the topic or channel is versioned, e.g., publishing v1 events to one topic and v2 events to another. But that can complicate subscriber management. A simpler approach is usually to keep one stream but include version info in the payload.
Because our architecture is highly decoupled, you can support multiple versions in parallel if needed. For example, if one internal consumer isn’t ready for a new format, you might (temporarily) have transform logic output both old and new events (or enrich old events with new fields but not remove old ones). The persistent canonical store could even store a superset schema that covers both versions, with nulls where not applicable.
It’s also useful to track the provider schema versions. If TicketSpice updates their webhook format, you should bump something on your side (even if just internally) to reflect you are now handling TicketSpice webhook v2. This can be documented in your code or config. Having tests for each provider’s payload examples is key so that when providers change payloads (which they do), you catch it and adapt your transformer.
In essence, treat the canonical schema as a public API for your internal systems. Apply API versioning best practices. Encourage consumers to be somewhat tolerant to minor changes (e.g., ignore unknown fields), but also maintain discipline that you don’t make sudden breaking changes without coordination.
Finally, ensure governance around the schema: typically a lead architect or team will own the canonical model to avoid random deviations. If each developer adds fields ad-hoc, you lose the consistency benefit. Instead, propose changes, review them (maybe with consumer input), update the schema documentation, then implement in transform and notify consumers.
The payoff of a well-defined canonical schema is huge: you get a clean contract with internal developers. It isolates them from the churn of external webhooks. For example, if Viator decides to rename a field in their webhook, you can adjust the transform to keep your canonical field the same, so none of your internal systems even notice – the anti-corruption layer doing its job. Internal systems see stable data and your integration team absorbs the external chaos.
Idempotency and Deduplication Logic
As touched on earlier, idempotency is crucial in webhook processing. Our architecture must gracefully handle duplicate deliveries of events, as well as ensure that reprocessing an event (whether manually or via retry) does not cause unintended side effects. Here we’ll outline concrete strategies for implementing idempotency in the ATP system.
Why duplicates happen: Most webhook providers send events at least once, and on errors they retry, potentially leading to duplicates. For example, if our endpoint was slow to respond or returned a temporary error, TicketSpice might resend the same “New Registration” event a few seconds later. We might then get the same event twice. Without idempotence, this could lead to double-processing (e.g., two entries in our database or two emails sent). Hookdeck’s guide emphasizes that “you will eventually get the same webhook multiple times” and that the application must be built to handle these scenarios.
General Strategy: The simplest strategy for idempotency is to assign each event a unique key and record the processing of that key. The key can be something provided by the webhook (ideal) or derived from it:
- Many providers include an event ID or request ID (e.g.,
X-Webhook-ID: abc123header). Always check the provider docs for this. If available, use it. As Hookdeck notes, “every provider will include some identifier for the webhook itself... repeated requests for the same webhook will have the same identifier”. - If no explicit ID, you can create a hash of the payload (like an MD5/SHA1 of the normalized JSON) as a best-effort identifier. This might generate false positives if payloads are identical for different events, but often is acceptable if no better key exists.
- Combine the provider name + event type + provider’s event ID (or hash) to form a composite key that’s globally unique in your system.
Store of Processed IDs: Maintain a data store of these keys that have been seen. A popular method is a relational table with the event key as a primary key.
When processing a new event, you attempt to insert its key. If the insert succeeds, it means it wasn’t seen before; you mark it as processed (and maybe update after successful processing). If the insert fails with a duplicate key error (or in some systems you do a select check first), it means this event is a duplicate and you should ignore it. The Hookdeck example demonstrates this using a SQL insert and catching a unique constraint violation. You could also use an upsert that does nothing if present. The point is, the database enforces uniqueness – which is reliable even across multiple distributed worker instances (contrasted with an in-memory set which wouldn’t be shared across processes).
Alternatively, a distributed cache like Redis could be used with a short TTL on keys – but TTL is tricky because you don’t necessarily know how long duplicates might arrive (usually duplicates come within minutes, but theoretically a retry could come much later). It’s safer to log it permanently, or at least for a long window.
When to do the check: You have a choice to do idempotency check at the ingestion stage or the processing stage:
- At ingestion: As soon as a webhook is received, check if its ID was seen, and if so, you could respond 200 OK and not enqueue it further. This saves downstream work. The downside is if the first processing attempt hasn’t completed yet (i.e., it’s in progress), a second duplicate might come in – the ingestion doesn’t know it’s currently being processed. In the DB approach above, you could insert the key before processing (with a “processing” status) so that a duplicate won’t even get enqueued. This is what the Hookdeck snippet did: they insert then proceed to handle, and if the insert fails, they silently ignore the webhook. This is efficient in not doing extra work, but you have to ensure to remove the key or mark it if the processing fails (so that you’d process a retry after a true failure).
- At processing: You enqueue everything, and when the transformer service pulls an event, it checks the DB. If already processed, it drops it (or just quickly moves on). This is simpler to implement in the centralized service and avoids having to handle partial processing states in the DB (because by the time it writes the key, the processing will be done, assuming single-thread for that event). It does mean a duplicate travels through queue and maybe raw store, but that overhead is usually minor.
Either approach can work; some systems even do both (belt and suspenders).
Idempotent Consumers: While we focus on the integration pipeline, note that idempotency can also be addressed or supplemented at the consumer side. For instance, an internal consumer of events might itself keep track of event IDs it processed, ignoring duplicates. This is a good secondary safety net, especially if consumers perform critical or irreversible actions. However, we prefer to eliminate duplicates upstream so consumers typically don’t even see them. Still, designing consumer logic to be idempotent (e.g., make database operations idempotent by using upsert or checking if a record exists before creating) is recommended, as a general resilience principle.
Handling Replays: Idempotency logic should also consider that we might intentionally replay events (from the raw store or DLQ). When we replay, we often want to process the event again (maybe after fixing a bug). If we reuse the same event ID on replay, the system might think it’s a duplicate and skip it. This could be undesirable if our goal is to correct something. To handle this, one approach is to have a notion of “replay mode” or a separate path. For example, if replaying events, maybe you publish them with a flag or to a slightly different bus endpoint. Or you temporarily disable the dedup check (dangerous globally, but maybe a targeted override). Another approach is if you truly want a “second pass” at an event, treat it as a new event with a new ID (but carrying the original ID internally for reference). This way, it flows through as a fresh event but you know it’s a replay of an older one. There’s no one-size-fits-all solution here, but it’s something to be aware of. Many times, replay is just re-sending missed events (which wouldn’t be in the processed DB anyway), so the duplicates check still protects from double-processing ones that were actually done.
Ensuring Idempotence in the Transform Process: The transform stage should be written to be pure and without side effects beyond publishing and storage. If you run it twice on the same input, it should produce the same output and not create double entries in the DB or double-send messages (the dedup ensures we don’t double-publish to the bus). Use transactions or upsert in the canonical DB insert to avoid duplicates there as well (for example, use the event ID as primary key in the canonical DB table too – then even if a bug or race caused two attempts to insert, one would fail or be ignored).
Testing Idempotency: In implementation, test by simulating duplicates. For instance, send the exact same payload twice to the ingestion and ensure that downstream, the event ends up published only once and stored once. Also test out-of-order duplicates (like send event, then after processing, send it again, see that second is skipped).
The bottom line: Idempotency is about safety and correctness. It turns the unpredictable delivery of webhooks into a reliable stream of unique events in our system. Without it, the rest of the pipeline could be undermined by repeats. With it, we can confidently process “at least once” inputs in an effectively once manner.
Raw Event Storage and Reprocessing
Storing raw events, as described in the persistence section, gives us the ability to reprocess events when needed. Let’s focus on how we can leverage this capability and what to consider when doing so.
Motivations for Reprocessing:
- Error Recovery: Suppose a bug in our transform logic caused some events to be processed incorrectly or even dropped. Once we fix the bug, we’d like to re-run those events to get the correct outcome. If we have the raw events saved, we can feed them back into the pipeline.
- New Consumers / Backfilling: If a new internal service is built and needs historical events (that were emitted before it existed), we can replay historical events into the bus so the new service can populate its data store as if it had been there all along.
- Data Corrections or Audits: Perhaps an external partner says “we think you missed some events last month” or an audit requires verifying processed data against source-of-truth. Raw logs allow us to rerun or compare events to ensure nothing was lost.
- Testing: In non-prod environments, you might take a set of raw events from production (scrubbed of sensitive info perhaps) and re-run them through a staging pipeline to test changes or measure performance.
Reprocessing Mechanism: The system should have a way to take events from the raw store and feed them into the transform process again. This might be a manual procedure or an automated one:
- A simple approach is a script or tool that reads raw events (maybe from a certain timeframe or matching a filter) and re-inserts them into the processing queue/topic. Care must be taken to mark them so that the ingestion stage doesn’t treat them as live webhooks. Usually, you’d bypass the external HTTP endpoint and directly enqueue to the internal queue with these raw events. Or you might have an admin endpoint on the ingestion service that accepts an event and goes through normal flow (with an admin key to authenticate it).
- If using cloud services, sometimes the providers offer replay features. For example, if using Kafka and you kept all events (raw or canonical) in a log, you could simply seek the consumer position back and re-consume. But in our scenario, we separated storage from bus, so the replay is a custom action.
- Dead-letter queue replay: If events landed in a DLQ (due to processing failures), one can often retry them automatically. Some systems let you requeue DLQ messages back to the main queue. That’s a subset of reprocessing (just the failed ones).
When reprocessing, ensure that the idempotency checks are considered. If these events were completely unprocessed originally (e.g., dropped before marking as processed), then it’s straightforward. But if they were processed and, say, produced a wrong result in canonical store or in a consumer, simply reprocessing might be seen as a duplicate (since event ID is already in the processed DB). If your goal is to correct data, you have to decide how to handle that. Possibly you’d treat it as a separate correction event. For instance, if an “OrderCreated” was processed with a wrong amount due to a bug, you might want to send a new event “OrderUpdated” with the corrected info, rather than replaying the same event ID (because consumers might ignore it as dup). Alternatively, you might purge the event from the processed DB (if safe) to allow reprocessing, but then consumers might think it’s a genuinely new event and double-count unless they also handle such corrections.
Because of these complexities, many systems lean towards sending explicit correction events or having idempotent consumer logic that can update state if the same event comes with changes. This is domain-dependent. In any case, raw data gives you the options – it’s up to the situation how to best utilize it.
Selective Reprocessing: You probably don’t want to blindly reprocess everything (unless recovering from a total data loss scenario). Usually, you filter which events to replay. For example, “reprocess all events from Oct 1st that failed transform” or “re-send all TicketSpice events of type X because we added a new consumer that needs past data of that type”. Thus, having a way to query the raw store is helpful. If raw events are in a database or easily queryable store, you can select those of interest. If they are in flat files, you might have to scan or know the keys. Maintaining some index or log of events by type/time in the raw store can expedite retrieval (even a separate small index DB mapping event IDs to object storage keys could help).
Data Privacy and TTL: One must be mindful of how long raw data is kept, especially if it contains personal information (like user emails, etc.). If users have GDPR or similar rights to erasure, storing raw events indefinitely might conflict with that unless you have a process to remove personal data from historical logs upon request. Some architectures choose to redact or tokenize sensitive fields in the raw store after a certain period, or not store extremely sensitive fields at all. These are considerations to balance audit needs vs privacy.
Testing Reprocessing Pipeline: It’s wise to test the reprocessing procedure in a staging environment to ensure it doesn’t break idempotency or overwhelm systems. For example, if you replay a large volume, ensure consumers can handle the flood (maybe throttle replays). Perhaps design the replay tool to pace events or do them in batches to avoid a sudden surge that could knock over a consumer expecting only real-time trickle. The architecture might allow using the same bus for replays or a separate channel – using the same ensures consumers don’t need to implement two code paths, but a separate “replay mode” channel could be given lower priority or a separate consumer group.
In conclusion, raw event reprocessing is a powerful safety net. It’s like having backups for your integration data. It turns “oops, we missed/ messed up those events” from a disaster to a manageable task. The ATP architecture’s inclusion of raw persistence is a deliberate choice to prioritize resiliency and auditability over a slightly simpler pipeline without storage. By planning the reprocessing mechanism and policies upfront, the team can respond to issues or new requirements much faster and with confidence that they have the data to do so.
Observability: Structured Logging, Tracing, and Error Tracking
For a mission-critical integration pipeline, observability is key. You need to know what’s happening inside the system – both for debugging issues and for monitoring health in real time. Observability in our ATP architecture includes logging, monitoring/metrics, tracing, and alerting.
Structured Logging: Each component (endpoints, transform service, etc.) should emit logs that are both human-readable and machine-parseable. Use structured logging (e.g., JSON log events or key-value pairs) so that your logging infrastructure (like ELK stack, Splunk, Azure Monitor, or CloudWatch Logs Insights) can filter and search easily. Important log fields might include:
- Event identifiers (the event ID, provider, type).
- A correlation or trace ID that links the logs of one event’s journey. For instance, when a webhook comes in, generate a GUID for that event processing and include it in all logs related to that event through ingest -> transform -> publish. This might be the same as the event ID if unique or a separate one.
- Timestamps of each stage (the time received, time queued, time processed, time published). From these you can derive latency metrics.
- Outcome of processing: success, or error details if failed.
- For errors, include as much context as possible (stack trace, error message, possibly the payload if not sensitive).
Having these logs means if someone reports “hey, we didn’t see X event processed,” you can search by maybe provider’s event ID or the order number in the payload, and find out if it hit the endpoint, if it was processed, where it might have failed, etc.
Distributed Tracing: In more complex setups, you might implement distributed tracing (using something like OpenTelemetry, Jaeger, Zipkin, or cloud provider’s tracing). For example, an incoming HTTP request to the endpoint gets a trace ID, which is passed along to the queue (maybe as part of the message metadata), then the transform service logs under that trace, and the publish step maybe logs it as well. This way, in a tracing UI, you could see a span for “TicketSpice webhook received” then a span for “processed and published to bus” as a chain. Tracing is especially useful if the pipeline grows to include more steps or if downstream systems also participate (you could trace from external event to internal processing to, say, the CRM system updating a record).
Metrics and Monitoring: It’s crucial to collect metrics like:
- Throughput: number of events received per minute (per provider, and total).
- Processing latency: time from ingestion to publish. You can measure e.g. at ingestion tag an epoch time in the message, and at publishing compute the difference. Or measure each segment: ingress time, queue wait time, processing time.
- Success/failure counts: number of successfully processed events vs number of errors.
- Queue length or backlog: e.g., number of messages in the queue waiting (to detect if you’re falling behind).
- Consumer lag: if using Kafka or similar, measure how far behind consumers are.
- Dead-letter count: how many events in DLQ (and alert if > 0 for example, because ideally that should be empty most of the time).
- External call metrics: maybe how many signature verifications failed (potential attack or misconfig), etc.
These metrics can feed dashboards. For instance, a dashboard might show per-provider event volume and any error spikes.
Crucially, set up alerts on certain conditions:
- If an endpoint starts returning non-2xx responses consistently (could indicate an issue with signature validation or downstream outage).
- If queue backlog grows beyond a threshold (maybe the processing can’t keep up).
- If any event fails to process (DLQ not empty or error count > 0 within X minutes).
- If processing latency goes beyond SLA (say if it normally takes 5 seconds from ingest to bus, but now it’s taking 1 hour, something is stuck).
- If duplicate events suddenly spike (could indicate an issue causing many retries).
- Security-related: if signature checks failing a lot (could be someone hitting endpoint with bad data).
The Hookdeck article excerpt underscores this: “Metrics and logs are collected throughout the system components. Metrics and logs are used to set up alerts for cases where administrators need to take action.”. This is exactly the goal of observability – not just to have data, but to drive alerts and actions when anomalies occur.
Error Tracking: In addition to raw logs, it’s useful to use an error tracking system (like Sentry, Rollbar, or Azure App Insights) to capture exceptions in a structured way. For example, if the transform service throws an exception for a particular payload, log it and also send it to an error tracker with context (so you can aggregate similar errors, see stack traces, etc.). This helps developers quickly pinpoint issues in code that need fixing. Since our pipeline is asynchronous, an error won’t directly alert someone without such tracking (unlike a web app where an error might show up to a user). So we must proactively catch and report errors internally.
Auditing and Traceability: Because we store events, we can always cross-verify that for every event stored raw, there is either a corresponding canonical record and a bus publish log or an entry in a DLQ log explaining failure. It’s good practice to periodically run an integrity check: e.g., ensure the count of raw events equals the count of processed events (minus those in DLQ). Any discrepancy might mean something got dropped silently. With proper error handling, that should not happen, but it’s a sanity check.
Performance Monitoring: Observability also covers performance. Monitor CPU/memory of your transform service, execution time per event (maybe histogram of processing times). If it starts creeping up, you might need to scale up/out or investigate inefficiencies. Also monitor the external calls – e.g., if writing to DB is slow or bus publish is slow, it will show in timings.
User Visibility: Sometimes, internal users or support might want to know the status of a particular webhook delivery. It could be nice to have a lookup tool (even a simple internal web UI or an API) where you can input a provider’s event ID or an order number and see the processing status (like “we received it at 10:00, transformed at 10:01, published to bus at 10:01, delivered to 3 subscribers by 10:02”). Building such a tool can use the logs or the database as a backend. This greatly helps in answering questions like “did we get that webhook? what happened to it?”
Correlation with Provider Logs: Some providers (like Stripe, etc.) have dashboards showing webhook delivery attempts and their status (e.g., delivered, failed, response code). It’s useful if you can correlate those with your system logs (e.g., by timestamp or ID) to investigate issues. For example, if the provider says “we retried 3 times and then gave up,” you might find that your endpoint was down during that window. With good logging, you’d see no trace of those attempts, which confirms an outage, etc.
In summary, observability is about knowing the pulse of your integration. By instrumenting the ATP pipeline with structured logs, metrics, and traces, and by setting up alerts, you ensure that when things go wrong (and eventually they will, be it a bug, a network issue, or a new event type you didn’t anticipate), you can quickly detect and diagnose the problem. This reduces downtime and builds confidence among stakeholders that the integration is under control. As a bonus, rich logs and metrics can also demonstrate the value of the system (e.g., “we processed 1 million events with 99.99% success last month”) – great information for leadership.
Security and Access Control
Security is paramount, as this pipeline deals with potentially sensitive business data and serves as a bridge between external and internal systems. We consider security in multiple facets: securing the intake of webhooks, protecting the integrity and confidentiality of data in transit and at rest, and controlling access to the internal bus and stores.
Webhook Endpoint Security (Authentication and Validation): As covered in the ingestion section, every incoming webhook request must be validated to ensure it’s legitimate. Rely on HMAC signatures or similar methods provided by the SaaS. For example, TicketSpice might allow setting a secret that they use to sign requests. Our endpoint uses that secret to recompute the signature and compare. If it doesn’t match, we reject the request (ideally with a 4XX status, though even a 200 and dropping it is fine for the attacker – but better the provider knows it was not accepted so probably 401). This is crucial; without it, an attacker could spoof events or flood your system with fake webhooks. The signature method (often SHA-256) is robust when implemented correctly. Follow the provider’s documentation precisely (e.g., some include a timestamp in the signature to prevent replay attacks; verify that too if required, such as only accepting if timestamp is within 5 minutes).
Additionally, use HTTPS for the webhook endpoints (which is typically mandated by providers anyway). This prevents eavesdropping or tampering in transit. If possible, restrict the firewall or API Gateway to only accept requests from known IP ranges of the provider (some providers publish IPs for webhook delivery). This is not always feasible (they might use dynamic cloud IPs), but if available, it’s another layer of defense.
Consider the case of Webhook denial-of-service (DoS): an attacker could send a flood of requests to your endpoint URL. Even if they can’t fake a valid signature (so we’d reject them), it could still load your network or processing. Using an API Gateway or WAF (Web Application Firewall) can help rate-limit or block IPs with too many failed requests. Our architecture naturally helps because we do minimal work on each request and can scale out the stateless ingestion, but it’s still good to have an eye on unusual traffic.
Data Security (Encryption and Storage): Ensure that any sensitive data in the events is handled securely:
- Data “in transit” internally (from the ingestion to queue, queue to processing, processing to bus) should ideally be encrypted. If using cloud services, many have this by default (e.g., AWS SQS, SNS encrypt data in transit with TLS and at rest with AES). If the components are within a VPC or secure network, it’s less exposed, but still, encryption doesn’t hurt.
- Data “at rest” in the raw and canonical stores should be encrypted (e.g., enable database encryption, or if using S3, enable bucket encryption). Most managed DBs and storage allow a toggle for encryption at rest.
- Access to those stores should be restricted. For example, only the integration service’s role can read/write the raw event bucket, not every developer or service in the company.
- If events contain PII (personally identifiable info) or other sensitive fields, consider masking them in logs (for observability, don’t log full credit card numbers or such). Also, perhaps implement data retention or deletion policies to comply with regulations (e.g., auto-delete or anonymize raw events after X days if not needed).
Message Bus Access Control: The internal message bus is like a central highway for event data. We must ensure only authorized components can publish or subscribe. Implement RBAC (Role-Based Access Control) on the bus:
- The ATP transform service (or whatever component publishes events) should have permission to publish to the specific topic. It should not necessarily have permission to consume from it (unless it also needs to, which it typically doesn’t).
- Each consumer service or team gets access only to the topic or subscription relevant to them. If using a shared topic with filtering, perhaps each subscriber gets their own subscription that only they can read.
- Use the principle of least privilege. For instance, if using Azure Service Bus, you might create a SAS (Shared Access Signature) token with publish-only rights for the producer, and listen-only rights for a subscriber on their subscription. Or if using AWS SNS, use IAM policies to allow only certain ARNs to subscribe or publish.
- Audit these access controls periodically. Many cloud event systems also let you enable logging of who accessed what, which can be useful for security audits.
Secrets Management: The webhook signing secrets (and any other credentials, like database passwords, etc.) should be stored securely, e.g., in a secrets manager service. They should not be hardcoded or in plaintext in config files. Only the functions that need them (the endpoint for signature, the DB connection for the service) should be able to read them at runtime.
Secure Deployments and IaC: Since we use IaC, ensure the templates also incorporate security best practices. For example, if deploying on AWS, ensure the Lambda has a policy that only allows needed actions (SQS send, SNS publish, etc., nothing more). If using container instances, ensure the host environment is secure, etc. Use read-only service accounts where possible.
Compliance and Audit: Depending on the industry, you might need to show that only authorized systems can access data. Our design by default funnels all external data into one pipeline which can be monitored. We can produce audit logs of who consumed what events by instrumenting the bus or requiring consumers to authenticate. Some message systems (like certain enterprise buses) can enforce that only certain microservices with specific certificates can connect. While possibly overkill for some scenarios, it’s good to know it’s achievable.
Webhooks Specific Security (additional): Some providers incorporate additional checks like a challenge-response (e.g., Slack sends a challenge on setup, expecting your endpoint to echo it). Our endpoint must handle such cases in provider-specific logic (likely during initial subscription setup) – just be aware in implementation but that’s a one-time thing per provider.
One more security aspect: schema validation as a security measure. If we expect a certain format from provider, we can validate the JSON structure upon receipt. This isn’t exactly security (more sanity check), but it can prevent unexpected payloads from causing downstream issues (and could detect if someone is sending malformed data intentionally). For instance, define a JSON schema for TicketSpice “New Registration” webhook and reject if required fields are missing. That ties into data integrity as well.
To summarize, the ATP pipeline must be secure by design at every layer: the door (webhook endpoint) is locked and only opens for the right key (signature), the inside channels (queues, bus) are guarded (access control, encryption), and the data stores are vaults (encrypted, limited access). Adopting these practices ensures that while we are moving potentially sensitive event data around, we are not introducing vulnerabilities. A breach or a misuse of this pipeline could be damaging (imagine fake events getting in, or confidential info leaking out), so security cannot be an afterthought – it’s built-in.
Extensibility: Adding New Webhook Sources with Minimal Changes
One of the strongest advantages of the Aggregate-Transform-Persist architecture is how it enables plug-and-play extensibility. Once the core framework is in place, adding a new webhook integration (a new source) should require minimal effort – primarily configuring the new source’s specifics – with no changes to the fundamental pipeline.
Here’s how the ATP architecture streamlines onboarding new providers:
- Standardized Ingestion Process: We already have an API gateway or endpoint mechanism for webhooks. To add a new provider, we simply deploy a new endpoint or route. Thanks to our use of templates/IaC, this might be as easy as copying an existing endpoint definition and changing a few parameters (like the provider name, the secret, and the URL path). The new endpoint ties into the same queue or messaging entry point that all others use. No new infrastructure needed – it’s reusing the existing queue and processing service. For example, if currently we have endpoints for TicketSpice and Viator feeding into an “inbound-webhooks” queue, adding Eventbrite could be done by adding an Eventbrite endpoint that also writes to that queue. The API gateway might route
/webhooks/eventbriteto the same handler function but with configuration for Eventbrite’s signature verification. All the common functionality (auth, enqueue) is reused. - Reusing Core Processing Logic: The aggregator/transform service is built to handle multiple providers. Typically, this means the code has a switch or registry of transformer modules keyed by provider and event type. To add a new provider, you create a new set of mapping rules or a module for it. For instance, implement
EventbriteTransformerthat knows how to parse Eventbrite’s payloads into your canonical events. Then register it in the service. If the design is plugin-friendly, you might not even need to modify core code – you could drop in a config file that describes Eventbrite’s mapping, and the core service reads it. But even if a code change is needed, it’s localized (e.g., add 50 lines handling Eventbrite, nothing about the overall flow changes). - No Changes to Bus or Downstream Contracts: The canonical schema is designed to be source-agnostic (it has a
sourcefield but otherwise each event type is defined by its business meaning). When we integrate a new provider, they will produce events that likely map to one of our existing canonical event types (or we may introduce a new event type if it’s a new kind of event). Importantly, we do not have to re-design how downstream services get events. They are already listening on event types, not caring if it came from TicketSpice or Eventbrite. For example, suppose both TicketSpice and a new platform Eventbrite send “Ticket Sold” events. Our canonical event might beTicket.Soldwith data fields like ticketId, eventId, price, etc. We simply map Eventbrite’s payload to the sameTicket.Soldevent. Internal consumers (maybe a finance system tracking sales) will automatically start receiving Eventbrite sales too, without even needing to know a new provider was added – except maybe thesourcefield now has “Eventbrite” entries in addition to “TicketSpice”. This is a big win: new integration, immediate value to existing consumers. - Minimal Config and Secrets: Each new provider likely brings a new secret or config (like distinct API keys for signature, maybe specific header names). The architecture isolates these in configuration files or secret stores. So adding a provider means adding an entry in a config (like
providers: [ name: Eventbrite, secret: XYZ, endpoint: /webhooks/eventbrite, expectedSignatureHeader: X-Eventbrite-Signature, ... ]). The core code can iterate over providers config to set up each endpoint and handle verification accordingly. This approach means no hardcoded logic per provider scattered around; instead it’s data-driven. - Scalable by design: Since the pipeline is generic and scaled horizontally, adding a new provider that increases volume just means more messages through the same pipeline. If needed, we scale up the consumers (e.g., increase number of transformer instances) but we do not need to redesign the pipeline. There’s one pipe that can handle more flow with simple scaling. Contrast this with a siloed approach where each integration might have needed a new dedicated pipeline – we avoid that duplication.
- Testing New Integrations: Because so much is reused, testing a new provider integration is simpler. You test that the endpoint receives and enqueues (which is usually boilerplate if done right) and test that the mapping outputs correct canonical events. You don’t need to retest the reliability aspects (dedup, bus, etc.) – those are already proven by existing ones. This again speeds up the onboarding of new sources.
- Example – Adding “Provider X”: To illustrate, let’s say we want to integrate a new SaaS called “ProviderX” that offers webhooks. What steps do we actually take?
- Obtain credentials/secret from ProviderX.
- In our configuration (perhaps a Terraform variable file and an application config file), add an entry for ProviderX including the secret and the events it will send (maybe a list of event types it has and how they map to our event types).
- Deploy – this creates a new HTTP endpoint
/webhooks/providerx(via our API Gateway module) and configures the lambda/ingestor to accept ProviderX webhooks. - Implement mapping: maybe ProviderX has a webhook for “item.sold” – we decide it maps to our
Ticket.Soldevent as well, or to a similarItem.Soldevent type. Write the transform function accordingly (or if using a low-code mapping, configure the field mappings). - Write unit tests using sample payloads from ProviderX to ensure the transformation is correct.
- Maybe do a test in a dev environment where we simulate a ProviderX webhook (or use ProviderX’s test mode) to ensure end-to-end it flows to our bus and a test subscriber sees it.
- Done – now enable in production and add the ProviderX integration in their UI (point their webhook to our new endpoint). The system will start handling them just like others.
In doing so, none of the existing provider logic was disturbed – so we haven’t risked regression on TicketSpice or Viator by adding ProviderX. And if one provider’s logic fails, it doesn’t directly affect others; e.g., a bug in ProviderX mapping might cause some ProviderX events to go to DLQ, but TicketSpice events still flow normally. This modularity ensures robustness as the number of integrations grows.
Documentation and Onboarding: The architecture also allows easier documentation for new sources – basically “to add a new source, do A, B, C” as above. Someone new to the team can follow a playbook. The canonical schema serves as the guide for what needs to be mapped. Over time, even less experienced developers (or potentially analysts if mapping becomes config-based) can onboard simpler integrations without deep changes.
Plug-in Architecture Consideration: In some advanced implementations, you can make the transform stage load “plug-ins” for new providers at runtime. For instance, have a directory of mapping rules where each provider corresponds to a config file. The core service reads all files and thus knows about all providers. Adding a provider then might not even require recompiling the service, just dropping a new config file and restarting. This is more relevant if you plan to integrate dozens of providers frequently. It trades some strict type safety for flexibility. Whether needed depends on context, but it’s something the architecture could accommodate.
Scalability of Management: As we add many providers, we should ensure things remain organized:
- Logging should always note which provider an event came from, so we can trace issues per provider.
- The idempotency store might use composite keys including provider to avoid any accidental collision (so two different providers’ events with same numeric ID don’t clash).
- Config files should be kept up to date and possibly refactored if they grow huge (maybe one file per provider).
- Also consider if multiple providers have very similar payloads (maybe because they’re in the same industry), we could reuse some transformation logic or share partial mappings. This avoids reinventing the wheel each time – though not always possible if formats differ.
In summary, the ATP architecture treats new webhook sources as first-class extensions, not one-off projects. The heavy lifting – reliability, queuing, bus integration, logging – is solved centrally, so each new integration mostly concerns itself with translation logic and configuration. This significantly reduces the time and effort to integrate new partners (potentially from weeks of development to just days or even hours for simpler ones). In business terms, this means faster onboarding of partners and integrations, giving the organization a competitive edge in being able to quickly connect with new services or clients.
Trade-offs and Considerations
No architecture is without trade-offs. It’s important to recognize the choices made in the ATP design and where one might choose a different path depending on priorities. Below are some key trade-offs and design considerations for the Aggregate-Transform-Persist approach:
- Centralized vs. Per-Source Processing:
Trade-off: We chose a centralized transform logic – one service (or group of identical services) handling all providers. The upside is consistency and code reuse: one place to implement cross-cutting concerns (auth, dedup, etc.) and a unified schema ensures all events look the same. It also simplifies adding new sources (as we discussed) and reduces infrastructure footprint (we don’t need 5 different pipelines for 5 providers). The downside is potential impact isolation: a bug in the central service could affect all integrations. For example, if the central service goes down, all provider webhooks are stalled; or if someone deploys a bad change, it could disrupt everything at once. In contrast, an alternative is per-source isolation – e.g., a separate microservice per provider’s webhook. That isolates failures (TicketSpice integration can fail while Viator’s still works) and allows optimizing or scaling each separately if one has much higher load. However, it incurs a lot of duplicate effort and complexity (each service needs its own queue, its own logging, etc., or they all have to reinvent the wheel, or you end up building a common library that is essentially doing what a central pipeline would do). Many organizations find a middle ground: a core framework (like our ATP) but perhaps deployed as separate instances for very high-volume or critical providers. In our context, centralizing the pipeline is likely more beneficial for maintainability, as long as we mitigate risks (thorough testing, maybe feature flags to turn off a problematic provider mapping if needed, etc.). Also, central doesn’t mean single point of failure if we run it redundantly – we can still have multiple instances for HA. - Replay and Recovery Complexity:
By storing events and enabling reprocessing, we gain power but also add complexity. Replaying events, as discussed, can lead to duplicates or logical issues if not done carefully. We have to design operational procedures (when to replay vs when to send a compensating event, etc.). This is a trade-off between a simpler pipeline that just processes in real-time and forgets (simpler, but if something goes wrong, data is lost) versus a more complex pipeline that can recover from issues (but requires operational know-how to use that capability correctly). We chose resiliency and traceability at the cost of extra components (storage, DLQ, replay scripts). For many businesses, this trade-off is worth it because data loss or inability to onboard a new system with historical data would be unacceptable. However, one should be aware that maintaining those raw archives and doing replays is a responsibility – you need to have monitoring for how far behind replays are, or clear documentation to avoid misusing it (e.g., an inexperienced engineer might re-run an entire year of events accidentally and overwhelm systems – controls or at least warnings should be in place). - Latency vs. Thoroughness:
Introducing asynchronous steps (queue, persistence) invariably adds some latency to the end-to-end delivery of events. In a direct synchronous integration, as soon as the webhook comes in, if you processed it in-process, you might update a system within, say, 500 ms. In our pipeline, we are optimizing for reliability, which means an event might sit in a queue for a short time, then be processed, then published, then consumed. In practice, if the system isn’t under heavy load, this latency can still be quite low (perhaps a few seconds). But under load or by design, we might be accepting a latency of, say, up to 1 minute or more from receive to final consumer processing, especially if we prioritize batching or if consumers are pulling on some interval. For most webhook scenarios (which are asynchronous by nature), a few seconds or tens of seconds is usually acceptable – they’re typically not used for user-facing immediate responses. As the TicketSpice documentation noted, webhooks shouldn’t be relied on for real-time workflows. So our design aligns with that. However, if you have a use case where near-instant reaction is needed (sub-second), an asynchronous persistent approach might conflict with that requirement. One might then skip some steps: for example, push events through a low-latency channel (like in-memory message bus) and maybe log asynchronously aside, to speed things up. That, however, can sacrifice reliability. So it’s a trade-off: speed vs. durability. We leaned towards durability. In practice, careful engineering and scaling can often ensure the latency stays low while keeping the safety nets – but it requires throughput capacity and possibly costs more in infra. - Complexity and Operational Overhead:
The ATP architecture, while extremely useful, is more complex than a trivial integration script. It involves multiple components (API gateway, queue, processing service, storage, bus, etc.). This means more things to configure and maintain. It’s a trade-off of initial complexity for long-term flexibility. For an organization with only one simple webhook a year, this might be over-engineering. But if you anticipate many integrations and high reliability needs, this overhead is justified. Still, it implies that the team needs to have (or develop) expertise in running message queues, debugging asynchronous flows, monitoring the pipeline, etc. It also means costs: each component (like a message broker or storage) could incur cloud costs. The design is scalable, but at small scale the overhead might be noticeable. The good news is many cloud services are pay-per-use, so if volume is low, costs remain low; and if volume grows (which presumably correlates with more business), the architecture can handle it. - Ordering and Consistency:
If events have relationships (say a “booking created” and “booking cancelled” event), our asynchronous pipeline might deliver them out of order to a consumer if not careful. Typically, within one provider’s feed, events are sent in order, and if we use one queue and one processing service, we’d dequeue in that order (assuming a FIFO queue or partitioning by key). But if we scaled out to multiple processing instances and events can be processed in parallel, there is a chance events from the same source interleave. For example, if not using FIFO, a cancellation could be processed before the creation if they were queued at nearly the same time and different workers picked them. Solutions include: use a FIFO queue (like AWS SQS FIFO or Kafka with key partitioning) keyed by something like object ID (booking ID) to ensure ordering per object. But that reduces parallelism for events of the same object, which is usually fine. This area is a trade-off between throughput vs. strict ordering. We may accept eventual consistency (processing things slightly out of order but correct it at consumer side) or we enforce ordering with potential throughput cost. In a lot of webhook cases, events are independent enough or infrequent enough that ordering isn’t a big issue, but it’s worth noting in design. The ATP pattern doesn’t inherently guarantee order unless you design for it. - Single Tenant vs. Multi Tenant Pipeline:
If our system is multi-tenant (i.e., handling webhooks for multiple clients or business units, which could happen if this is a central enterprise service), one might consider isolating by tenant for security or noise isolation reasons. The trade-off here is similar to per-source isolation: either one pipeline handles all tenants (with a tenant ID as part of event data) – simpler, but a bug could leak events across tenants if not careful – or you deploy separate pipeline instances per tenant – which is more overhead. We won’t dive deep here as it’s not explicitly asked, but it’s a consideration if relevant (mostly in SaaS scenarios where you might be receiving webhooks on behalf of many customer accounts). - Build vs. Buy:
As a side note, given the complexity of webhook handling, some might consider using a third-party webhook management service (like Hookdeck, Zapier, etc.) which can handle some of these aspects. That’s a different trade-off (outsourcing infrastructure vs. building in-house). The ATP architecture described is a custom in-house solution, which often is justified for maximum control, security, and integration with internal systems. But it’s good to acknowledge that the team must maintain it. The benefit is, by building it, you can highly tailor it to your needs (and likely save cost in the long run if you have high volume, since third-party services can charge per event). - Maintenance of Canonical Schema:
With a canonical schema, we have a contract to maintain internally. There’s a bit of a trade-off in flexibility. If an internal consumer says “I want this exact field from Provider X’s payload and it’s not in the canonical schema,” we either have to extend the schema or tell them to derive it differently. We lose some raw fidelity in favor of consistency. In most cases that’s fine, but it could mean sometimes canonical schema lags what providers offer (until you version up). The alternative (passing raw through) would give flexibility but burden every consumer with parsing variety – which we clearly wanted to avoid. So we accept that schema governance might require coordination.
In conclusion, while the ATP architecture brings significant robustness and agility, it comes with increased system complexity and a slight performance cost due to the asynchronous, persistent nature. These trade-offs are usually acceptable in exchange for the reliability and extensibility gains, especially in integration-heavy environments. Each organization should weigh them – for example, if you only ever expect one consumer and low volume, a simpler direct approach might do. But if you expect growth (more providers, more consumers), this pattern positions you to handle it with grace. The trade-offs we discussed were consciously chosen to favor long-term scalability, data integrity, and decoupling over short-term simplicity.
Conclusion: Strategic Business Value
Implementing an Aggregate-Transform-Persist architecture for webhook processing is not just a technical endeavor – it delivers clear strategic value to the business. By investing in this robust integration framework, an organization sets the stage for faster partnerships, greater resilience to change, and improved operational insight. Let’s recap the key benefits in business terms:
- Faster Partner Onboarding: In competitive markets, the ability to quickly integrate with new platforms, vendors, or clients can be a game-changer. With the ATP system in place, adding a new webhook source is routine rather than a project. This means what used to take weeks of custom development for each partner can potentially be done in days. For the business, that translates to faster time-to-market for new integrations, enabling the company to seize opportunities (or comply with partner requirements) with minimal delay. It also means the integration team can handle more projects in parallel since each new addition is incremental work, not a from-scratch build.
- Resilience and Reliability: The architecture is built to handle failures gracefully – queueing ensures that transient outages (either on our side or even slowdown on a consumer side) do not cause data loss or system crashes. Retries and idempotency ensure that even if providers send duplicates or our service restarts, the outcome remains correct. This robustness directly supports business continuity. For example, if a downstream CRM system is temporarily down, events will wait in the bus until it recovers, rather than being lost – no manual data entry later to fill gaps. The presence of dead-letter queues and monitoring means any issues are caught and can be resolved before they become crises. Overall, the business can trust that “webhook-driven processes” (like orders, notifications, syncs) will happen reliably, which is essential for customer satisfaction and operational efficiency.
- Adaptability to Change: In the tech world, APIs and webhooks evolve. Providers might change their formats, add new event types, or new consumer needs emerge. The ATP architecture’s decoupling and canonical model make the system adaptable. External changes are absorbed in the transform layer without rocking the whole boat. Internal changes (like swapping out a consuming system or adding one) are just new subscriptions to the bus. This loose coupling fosters innovation – teams can build new event-driven features tapping into the event bus without fear of breaking others. The business gains agility, being able to rewire processes or add analytics on events with minimal friction.
- Transparency and Traceability: The comprehensive logging, persistent storage, and structured events provide end-to-end traceability. If a stakeholder asks “Did we process all the orders from Partner X yesterday?”, the answer is readily available with data (we can show exactly what was received and how it was handled). This traceability not only aids troubleshooting but also provides confidence to partners and auditors. In regulated industries, being able to demonstrate an audit trail of events can be a compliance requirement – our architecture inherently provides that. Internally, this transparency means less time spent on “investigative drama” when something goes wrong; issues can be pinpointed and addressed quickly, which keeps operations smooth and customers happy.
- Maintainability and Ownership: By consolidating webhook handling into a single well-defined system, the codebase and infrastructure become easier to maintain in the long run. We avoid a tangle of miscellaneous scripts or one-off integrations. The team can focus on one robust pipeline, apply updates in one place, and upgrade infrastructure (say, move to a new queue tech or bus) systematically. This central platform encourages a center of excellence around integrations – knowledge is concentrated, patterns are reused, and new team members have a clear framework to learn. Over time, this reduces the technical debt and cost of ownership compared to having disparate integration points.
- Scalability for Growth: As the business grows, the volume of events may surge, or new use cases may require more complex processing. The ATP architecture is inherently scalable: each component (gateway, queue, processor, bus) can be scaled out horizontally or upgraded. Want to handle 10x events? Add more consumer instances or partition the queue. Need to integrate 5 more SaaS products? Add their configs; the pipeline handles it. This means the architecture won’t become a bottleneck to growth – it’s a backbone that can carry increasing load with predictable adjustments. Strategically, the business can be confident that increasing integration demands won’t linear-increase the headache; the platform approach yields economies of scale in integration efforts.
- Improved Collaboration and Data Utilization: With an event bus in place publishing canonical events, different teams can tap into events for their own innovation. Maybe the marketing team realizes they can listen to “Ticket Purchased” events to trigger a post-purchase email campaign. Or the data science team subscribes to events to feed a real-time dashboard of key metrics. The availability of clean event data enables cross-functional projects and insights that might have been hard to get if data was siloed in each integration’s custom code. This turns integration from a back-end plumbing task into a value-generating data pipeline for the whole company.
In closing, the Aggregate-Transform-Persist architecture elevates webhook handling from a patchwork of point solutions to a strategic integration platform. It provides reliability and confidence (so the business isn’t worried about missing critical notifications), speed and agility (so the business can integrate and react quickly in a fast-moving ecosystem), and clarity (so the business and technical teams have full visibility into the flow of events). While it requires upfront investment and thoughtful design, the payoff is a system that grows with the business and significantly lowers the long-term cost and risk of integrating with third-party services.
By adopting this pattern, technology leadership signals a proactive stance: rather than reacting to integration needs with one-off fixes, the company builds a resilient highway for all current and future webhooks. This ultimately leads to faster partner onboarding, increased resilience, complete traceability, and easier maintainability, aligning IT capabilities with business objectives and enabling the organization to focus on leveraging data, not wrangling it. The ATP architecture thus becomes a competitive asset, turning integrations into a strength rather than a pain point.